
MySQL 主键生成策略对索引结构和性能的影响
编辑在工作的时候接触到了分布式 ID 中间件,对其原理比较感兴趣,遂进行了一番研究。
从主键自增开始聊起
众所周知,MySQL 使用的 InnoDB 存储引擎,底层索引的结构是优化后的 B+ 树。如果表使用自增主键,那么每次插入新的记录,记录就会顺序添加到当前索引节点的后续位置。当一页写满,就会自动开辟一个新的页。
这样就会形成一个紧凑的索引结构,近似顺序填满。由于每次插入时也不需要移动已有数据,因此效率很高,也不会增加很多开销在维护索引上。
如果使用非自增主键(例如 UUID),由于每次插入主键的值近似于随机,因此每次新纪录都要被插到现有索引页得中间某个位置:此时 MySQL 不得不为了将新记录插到合适位置而移动数据,甚至目标页面可能已经被回写到磁盘上而从缓存中清掉,此时又要从磁盘上读回来,这增加了很多开销。同时频繁的移动、分页操作也会造成大量的碎片。
我这里将设计一个测试,分别用主键完全自增和主键完全随机的方式,使用 Navicat 运行 SQL 脚本的插入 500w 行数据。
准备库表
CREATE TABLE `general_ordered` (
`id` int NOT NULL COMMENT '主键',
`name` varchar(32) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NOT NULL COMMENT '用户名',
`password` varchar(32) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NOT NULL COMMENT '加密后的密码',
`salt` varchar(32) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NOT NULL COMMENT '加密使用的盐',
`email` varchar(32) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NOT NULL COMMENT '邮箱',
`phone_number` varchar(15) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NOT NULL COMMENT '手机号码',
`status` int NOT NULL DEFAULT 1 COMMENT '状态,-1:逻辑删除,0:禁用,1:启用',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`last_login_time` datetime NULL DEFAULT NULL COMMENT '上次登录时间',
`last_update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '上次更新时间',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb3 COLLATE = utf8mb3_general_ci COMMENT = '测试表' ROW_FORMAT = DYNAMIC;
这里准备了一张数据库表,模拟了常见的存储用户信息的业务场景。
生成 SQL 语句
使用 Java 代码生成两个含有 500w 行 insert 语句的 .sql 文件,其中,主键的生成方式分别为完全自增和完全随机:
package dev.rennen.mybatis_test_01;
import java.io.BufferedWriter;
import java.io.FileWriter;
import java.io.IOException;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.Set;
public class SqlBatchGenerator {
// main 函数
public static void main(String[] args) {
ordered("inserts_ordered_500w.sql");
suffix("inserts_suffix_500w.sql");
}
private static void ordered(String fileName) {
// 使用BufferedWriter来写入文件
try (BufferedWriter writer = new BufferedWriter(new FileWriter(fileName))) {
for (int id = 0; id <= 5000000; id++) {
String sql = generateSqlStatement(id, "ordered");
writer.write(sql);
writer.newLine();
}
System.out.println("SQL语句已生成完毕并写入到文件:" + fileName);
} catch (IOException e) {
e.printStackTrace();
}
}
private static void suffix(String fileName) {
// 使用BufferedWriter来写入文件
try (BufferedWriter writer = new BufferedWriter(new FileWriter(fileName))) {
Set<Integer> ids = new java.util.HashSet<>();
for (int i = 0; i < 5000000; i++) {
int id = (int) (Math.random() * Integer.MAX_VALUE);
if (ids.contains(id)) {
i--;
continue;
}
ids.add(id);
String sql = generateSqlStatement(id, "suffix");
writer.write(sql);
writer.newLine();
}
System.out.println("SQL语句已生成完毕并写入到文件:" + fileName);
} catch (IOException e) {
e.printStackTrace();
}
}
private static String generateSqlStatement(int id, String tableName) {
// 这里使用当前时间作为创建时间、最后登录时间和最后更新时间
SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
String currentTime = dateFormat.format(new Date());
// 根据 id 生成 SQL 语句,每个 INSERT 语句只插入一条记录
return String.format(
"INSERT INTO `primary_id_test`.`%s` (`id`, `name`, `password`, `salt`, `email`, `phone_number`, `status`, `create_time`, `last_login_time`, `last_update_time`) "
+ "VALUES (%d, 'testSave', '24fae46ba1ef6fc40b479d6bcc856970', '7abe8aa1d04a45208f5c53d48a845a21', '[email protected]', '17300000000', 1, '%s', '%s', '%s');",
tableName, id, currentTime, currentTime, currentTime
);
}
}

生成的两个文件大小一共 3.53 GB……
接下来要做的事情就是在 Navicat 中建表,并执行 .sql 文件。
先来比较执行速度:
主键完全单调自增,插入 500w 条数据,用时 8 分 11 秒,比我想象的要快很多:
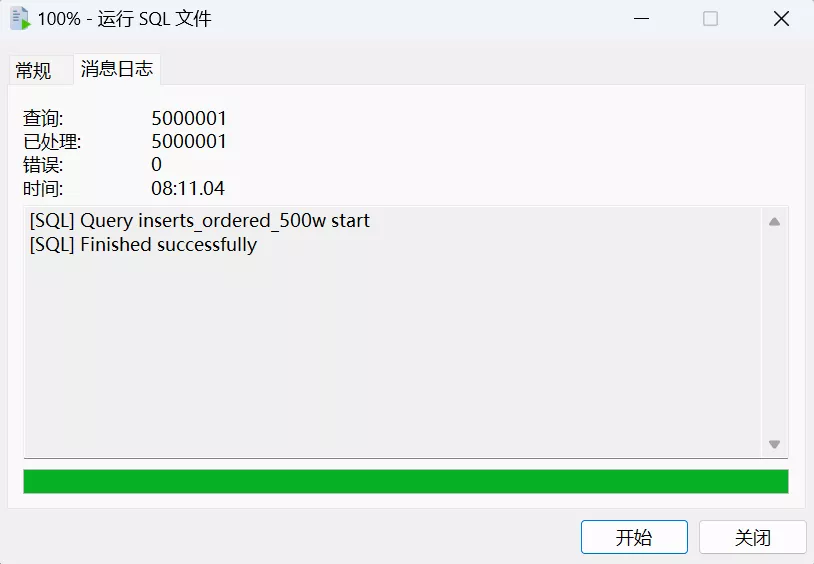
主键完全随机,插入 500w 条数据,竟然用时 53 分钟:
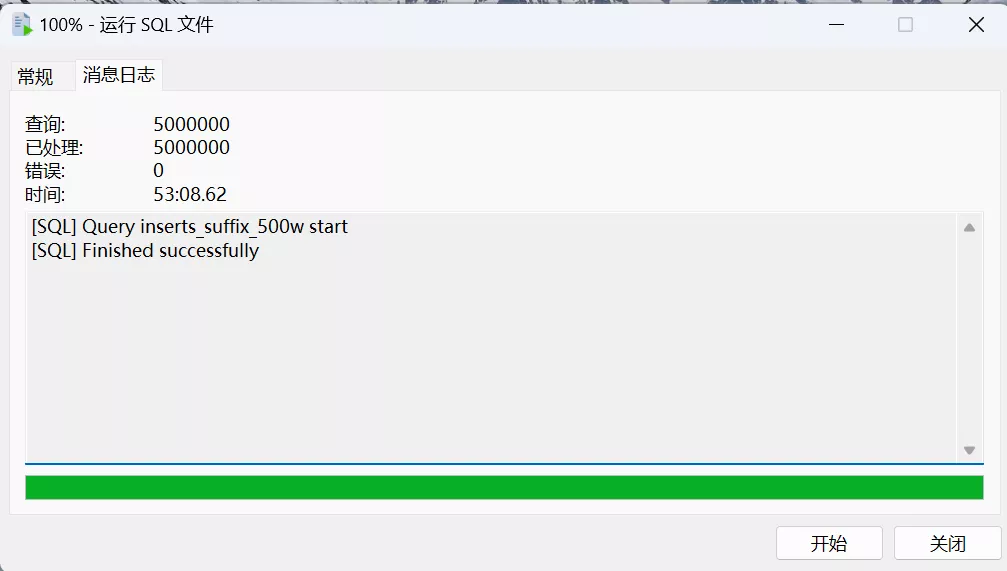
这里尽管实验设计不太严谨,同时也只做了一次测试,但还是可以看出主键自增和主键随机在速度上的差距还是非常大的。而且通过肉眼观察,主键自增的插入速度从头到尾都是一致的,而主键随机的插入速度,前五分之一(前一百万)非常快,只用了四分钟左右,剩余的时间都在插入后四百万数据。
特别注意的是,此次测试的环境是 PCIE 4.0 SSD,CPU 为 AMD Ryzen 7 8845H。因此我认为结果不具有代表性。如果使用配置稍差的平台(比如传统机械硬盘),两次测试的差异应该会更加明显。
接下来再比较索引节点个数和索引大小。在这之前,需要额外补充一下:MySQL 中的数据是以数据页的形式进行存储,一个数据页的大小为 16K,数据页和数据页之间是以 B+ 树的形式进行关联,叶子节点的数据页存放的是实际存储的数据,非叶子节点存放的是索引内容。
可以在 MySQL 的安装目录下看到整个索引文件的大小:
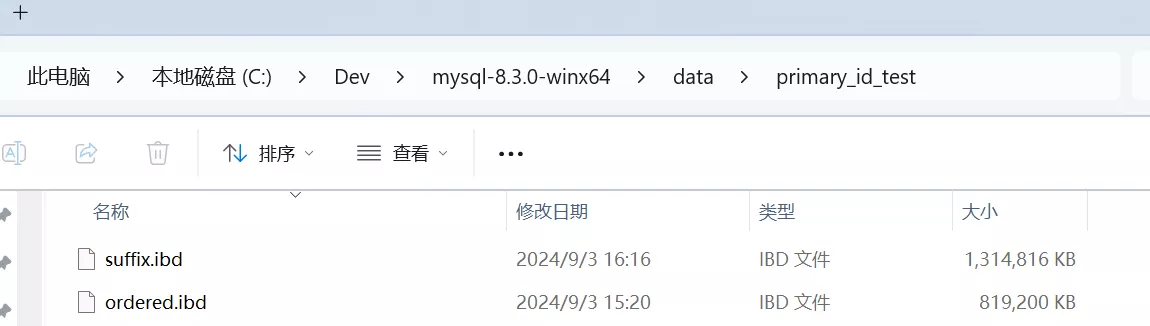
发现同样存储 500w 条数据,主键自增的索引大小为 800M,而主键随机的索引大小为 1.25GB,是主键自增的近 1.5 倍
我们还可以通过 mysql/innodb_index_stats 这张表看到索引结构情况。

其中,n_diff_pfx01 表示索引中第一个列的不同值的数量,是基于对索引页的随机采样来估计的,不是真实值;n_leaf_pages 代表 B+ 树中叶子节点的个数;size 代表 B+ 树中所有节点的个数。
可以看出索引节点的个数,和索引文件大小基本对应,值得注意的是非叶子节点数和总节点数的比值,后者的比值要更大,也就是更多的节点被用来存放索引结构。
再谈分布式 ID
在我们开发的过程中,随着项目的数据量不断增加,单一数据库的存储和查询性能可能逐渐下降。此时可以将数据按照一定的规则拆分到多个表中,每个表存储部分数据,从而分散数据的存储压力,提高查询性能。
分表过后,就不能使用数据库主键自增作为 ID 了。因为如果这样的话不同的分表都维护着一个自增 ID,肯定会有冲突。所以我们需要引入一个分布式 ID,这个分布式 ID 第一个需要满足的特性就是全局唯一。毕竟尽管分了表,但逻辑上我们还是要将其看作是一张表,只有全局唯一我们才能确定唯一的一条记录。
同时,我们也希望该分布式 ID 是单调自增的(起码在一个分表上单调自增)。毕竟刚刚通过测试我们已经得出来了 ID 单调自增的好处。
然而,实际上我们使用的分布式 ID 往往并不是完全单调自增的,而是趋势自增的。趋势自增即:局部来看,生成的 ID 序列并不完全单调自增,但整体来看又是趋势自增的。
为什么呢?我们可以设想一种用 Redis 实现的完全单调自增的分布式 ID 生成方案,使用 Redis 的自增命令 INCR 来生成唯一且单调自增的 ID。每次需要生成新 ID 时,客户端通过调用 Redis 的 INCR 命令,对某个键的值进行递增,返回的结果即为唯一且单调自增的 ID。原理大概如图所示:
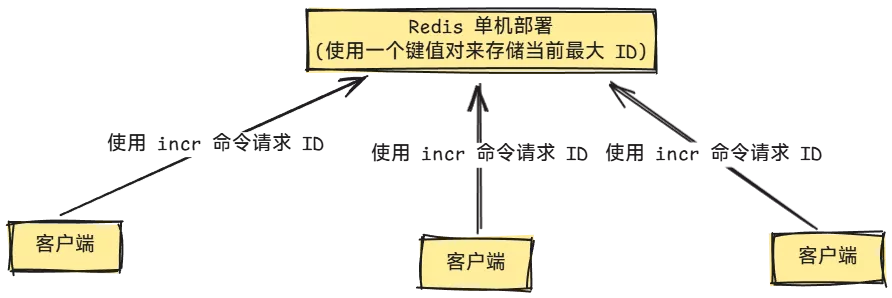
如果这样设计会有什么问题呢?
首先是保证不了高可用,如果 Redis 挂了,那么客户端也就无法获得 ID 了。
如果引入哨兵模式来保证高可用呢?那么客户端还是得从主库执行 INCR 命令,从库只是起到一个主库挂了顶上去的作用。尽管 Redis 天生适合高并发的场景,单一实例的并发量也是有上限的。当请求 ID 的客户端数量增多,作为发号器的 Redis 就会成为整个业务中的瓶颈。
这里引用一句在美团 Leaf 分布式 ID 项目下面的讨论:全局 ID 单调递增(性能)问题,可以最终简化为(分布式/高性能)文件系统的读写原子性问题。比如一个文件记录着当前最大ID。
况且,在分布式高并发场景下,就算实现了全局 ID 单调递增,考虑到「获取 ID」和「记录入库」并不是一个原子性的操作,那么获取 ID 的顺序和对应的记录入库的顺序也就不一定相同。 因此,我们没必要在分布式 ID 中实现全局 ID 单调递增。
两种常见分布式 ID 方案
接下来我们讨论两种常见的趋势自增的分布式 ID 生成方案,分别为雪花算法和号段模式。
雪花算法
首先以著名的雪花算法为例,其原理如图: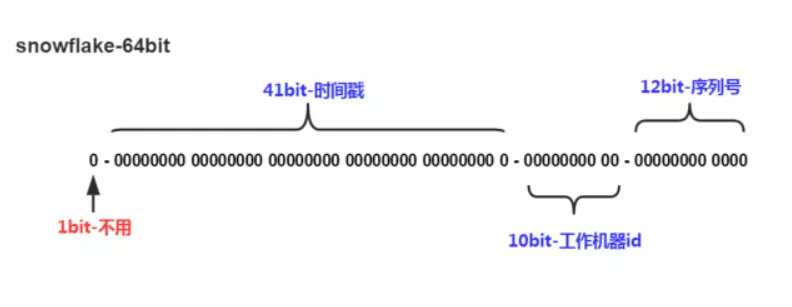
可以看到雪花算法由时间戳、工作机器 ID、序列号三部分组成,看起来好像是唯一且自增的。
然而实际上,不同机器的时间很难保证完全一致,偏差从几毫秒到几秒都有可能。因此,雪花算法是虽然实现了全局唯一的特性,但其并不是单调自增的,而是趋势自增的。
号段模式
再看一种号段模式的分布式 ID 自增实现,包括美团的 Leaf、滴滴的 Tiny ID、得物的自研分布式 ID 中间件都是这种实现。以 Leaf 为例,具体原理请看官方的介绍,以下为简述:
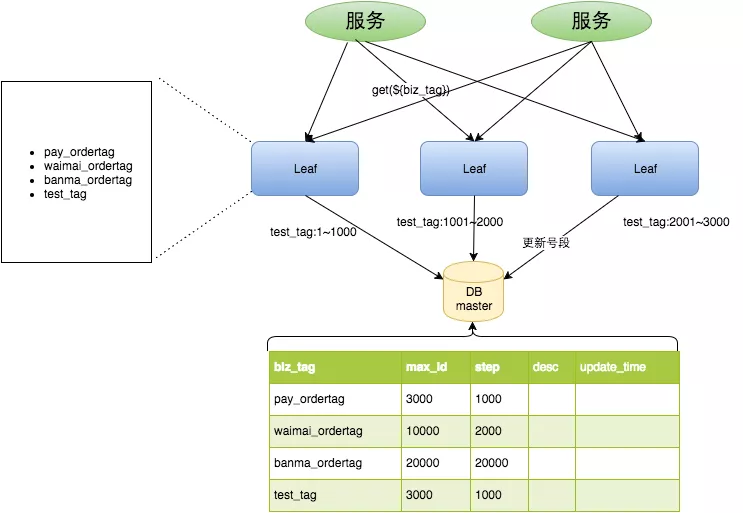
每个 leaf-server 每次从 DB 获取 1000 个号码,请求分布式 ID 的客户端经过负载均衡路由向 leaf-server 集群请求获取一个 ID,当一个 leaf-server 的号段用完(或者即将用完),就会向服务器申请新的号段。整个系统实现了高并发和高可用,生成的 ID 是趋势自增的。
问题来了,这种趋势自增的插入方式会对插入速度和索引大小造成影响吗?
还是使用同样的方式,按照上图模拟 3 个 leaf-server,2 个线程。使用 Round-robin 也就是轮询的负载均衡。步长设置为 1000,也就是每个 server 依次获取长度为 1000 的号段,所有 leaf-server 最多生成 500w 个 ID。同时为了方便起见,假设暂时不做分库分表,只有一张表,且获取 ID 的顺序和记录被插入到数据库的顺序是一致的。
生成含有 500w 行 INSERT 语句的 .sql 文件的 Java 代码如下:
private static void generalOrdered(String fileName) {
// 使用BufferedWriter来写入文件
try (BufferedWriter writer = new BufferedWriter(new FileWriter(fileName))) {
// 2 个 Thread 代表请求 ID 的客户端
List<Thread> threads = new ArrayList<>(2);
// 3 个 IDGenerator,相当于 leaf-server
List<IDGenerator> generators = new ArrayList<>(3);
CountDownLatch latch = new CountDownLatch(2);
for (int i = 0; i < 3; i++) {
generators.add(new IDGenerator());
}
for (int i = 0; i < 2; i++) {
threads.add(new Thread(() -> {
int count = 0;
while (true) {
// 客户端使用轮询的方式依次请求每一个发号器,获取号码
IDGenerator currentGenerator = generators.get(count++ % generators.size());
int id = currentGenerator.getAndIncrement();
if (id == -1) {
// 遍历其他发号器,看还有没有号码
boolean flag = false;
for (IDGenerator generator : generators) {
id = generator.getAndIncrement();
if (id != -1) {
flag = true;
break;
}
}
if (!flag) {
// 500w 个号码已经全都分配完了,线程停止运行
break;
}
}
// 生成 SQL 语句并写入到文件中,具体可以看上一个代码块
String sql = generateSqlStatement(id, "general_ordered");
synchronized (writer) {
try {
writer.write(sql);
writer.newLine();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
latch.countDown(); // 表示线程运行完
}));
}
for (Thread thread : threads) {
// 启动两个线程
thread.start();
}
// 主线程等待,直到 CountDownLatch 计数器减为 0
latch.await();
System.out.println("SQL语句已生成完毕并写入到文件:" + fileName);
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
static class IDGenerator {
private static final AtomicInteger totalCount = new AtomicInteger(); // 当前的全局 ID 起始值(模拟存储在数据库中)
private static final int length = 1000; // 步长(每个号段的长度)为 1000
private static final int maxLength = 5000000; // 最多生成 500w 个 ID
private int segmentInitialValue; // 当前分配到的号段初始值
private int currentCount; // 当前号段内的计数
public IDGenerator() {
segmentInitialValue = totalCount.getAndAdd(length);
currentCount = 0;
}
/**
* 从自己内部缓存的号段中获取 ID,如果号段用完则从数据库获取新的号段,简单加锁保证并发安全
* @return 获取到的 ID
*/
public synchronized int getAndIncrement() {
if (segmentInitialValue >= maxLength) return -1;
if (currentCount >= length) {
currentCount = 0;
// 当前号段用完了,从数据库中新获取分配一个号段
segmentInitialValue = totalCount.getAndAdd(length);
if (segmentInitialValue >= maxLength) return -1;
}
return (currentCount++) + segmentInitialValue;
}
}
运行生成的 .sql 文件并分析结果:
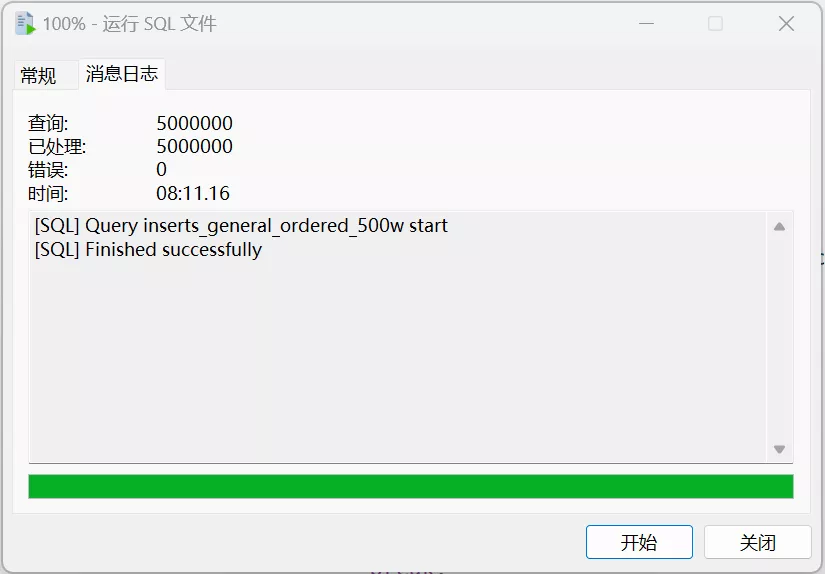

上面的测试结果可以看到,趋势自增的总用时和完全自增几乎一致,但索引结构的大小相比完全自增还是高了一大截。也就是说,趋势自增的插入时间接近完全自增,但索引结构还是过于庞大,不够紧凑。
针对上面的现象,我的解释是:在 MySQL 中,Buffer Pool 的默认大小其实是很大的,足足有 128 MB。因此,趋势自增仍然能够利用在 Buffer Pool 中缓存的页数据(可以理解为要插入的记录总是对应的是那些相同的数据页,缓存的命中率更高,因此缓存的数据页能够重复利用,而不至于马上回写到磁盘中),但是由于趋势自增终究不是完全自增,所以仍然避免不了页分裂产生的数据空洞,因此索引占用的空间会更大。
总结
最后请 AI 对本文做一个总结:
本文探讨了分布式 ID 生成方案,特别是 MySQL 中使用自增主键与非自增主键(如 UUID)对数据库性能的影响。通过实验比较,发现自增主键在插入速度和索引大小上具有明显优势。文章进一步讨论了分布式系统中实现全局唯一且趋势自增的 ID 生成方法,如雪花算法和号段模式,以及它们对性能和索引结构的影响。最后,通过模拟测试,验证了趋势自增 ID 生成方案虽然接近自增 ID 的性能,但索引结构仍不够紧凑,指出了分布式 ID 生成方案在实际应用中的权衡和选择。
后记
这篇文章其实五月份就写完了,今天下午又修修改改了很多部分,终于能发出来了。至此博客终于有了一篇像样的技术文章。由于水平有限,存在错误在所难免。如有纰漏欢迎指正!
本文还有待完善的地方,之后可能会更新一个散点图,来更好地展示趋势自增到底是怎么一个趋势。就目前来看,ID 序列构成的散点图近似一条很粗的直线。
之后也会将代码上传到 Github 上。
参考资料
- 2
- 0
-
分享